Progress Report on CppCMS v1
Its quite long time that most of the work is done in new refactoring branch... Meanwhile trunk stays silent. So, I decided to open a window and show some new changes:
Dependencies:
I had removed almost all dependencies with a big exception of Boost libraries.
Because of internal structure changed --- mostly introduction of asynchronous event handling I could not use existing implementations of FastCGI because of its synchronous API. Also I decided to remove CgiCC that was very problematic in terms of installation, portability and most important the quality of implementation and ability to communicate with its primary developer.
So, at this point you only need latest boost library... Thats all. When the job would be complete it would be very easy to create deb/rpm packages for most popular distributions.
Server APIs:
In addition to supported FastCGI and SCGI protocols, direct HTTP protocol is supported, so you do not need to use external web server for debug purposes any more. It is also useful for embedding web applications.
Localization is now fully integrated with C++
std::localeand allows using correct facets for each supported language and translationWindows is now would be one of the officially supported platforms.
There is still lot of work to make new version as useful as current CppCMS stable version:
- Integrate all template system back.
- Integrate cache and sessions management back.
- Rewrite forms classes that currently work with CgiCC.
- Rewrite support of CGI API for embedded systems.
But there are many good points that are already visible.
Boost Namespace Renamer
I had written a little Python script that solves the collision problem of different versions of Boost library, it is especially critical for library project that aims to provide backward binary compatibility.
Script source: http://art-blog.no-ip.info/files/rename.py
Running:
./rename.py /path/to/boost/tree new_namespace_name
Notes:
- No guaranteeing, if this scripts eats your cat or destroys all your source, it is Your problem.
- It is quite an initial version, but I managed to build most important Boost libraries like: thread, program-options, system, iostreams, date-time, regex, serialization, signals and run some regression tests.
- This script does not update Jam files, so, some conditional stuff(like symbol exports for DLL) would probably not work. I assume that each project that pics some code from Boost, provides its own build system.
What's Next?
The road map of the project includes two important milestones:
- CppCMS core components refactoring including following:
- Removal of dependency on CgiCC -- today there is about 5% of CgiCC library is used, many features are not supported by it or are not supported well. For example: file upload handling in CgiCC is very primitive, limited and error prone, support of cookies buggy and so on.
- Using of Boost.Asio as internal event handler, because:
- It provides transparent synchronous and asynchronous event handling allowing future implementation of server push technologies.
- It provides efficient timer based event handling.
- Removal dependency of libfcgi and writing Boost.Asio friendly implementation of FastCGI/SCGI connectors. Implementation of HTTP connectors as well.
- Support of plug-in applications in CppCMS framework.
- Improving compilation speed by representing more
pimplidioms and removal of unnecessary classes.
- Better support of i18n and and l10n:
- Transparent support of
std::wstringwith forms including automatic encoding testing and conversion. - Support of
std::localefor localization for outputs like numbers, dates, monetary, translation and so on. - Optional support of ICU and icu::UnicodeString and icu::Locale that
would add unsupported features by
std::localeand allow replacementstd::localefeatures with more correct implementations provided by ICU.
- Transparent support of
These changes will significantly break API backward compatibility, but it would be possible to adopt the code almost "mechanically" to the new API.
Unicode in 2009? Why is it so hard?
From my point of view, one of the most missing features in C++ is the lack of good Unicode support. C++ provides some support via std::wstring and std::locale, but it is quite limited for real live purposes.
This definitely makes the life of C++ (Web) Developers harder.
However there are several tools and toolkits that provide such support. I had checked 6 of them: ICU library with bindings to C++, Java and Python, Qt3 and Qt4, glib/pango and native support of Java/JDK, C++ and Python.
I did little bit challenging test for correctness:
- To Upper: Is German ß converted to SS?
- To Lower: Is Greek Σ converted to σ in the middle of the word and to ς at its end?
- Word Boundaries: Are Chinese 中文 actually two words?
Basic features like encoding conversions and simple case conversion like "Артём" (my name in Russian) to "АРТЁМ" worked well in all tools. But more complicated test results were quite bad:
Results
| Tookit | To Upper Case | To Lower Case | Word Boundaries |
|---|---|---|---|
| C++ | Fail | Fail | No Support |
| C++/ICU | Ok | Ok | Ok |
| C++/Qt4 | Ok | Fail | Ok |
| C++/Qt3 | Fail | Fail | No Support |
| C/glib+pango | Ok | Ok | Fail |
| Java/JDK | Ok | Ok | Fail |
| Java/ICU4j | Ok | Ok | Ok |
| Python | Fail | Fail | No Support |
| Python/PyICU | Ok | Ok | Ok |
Description
ICU: Provides great support but... it has very unfriendly and old API in terms of C++ development. The documentation is really bad.
Qt4: Gives good results and friendly API, has great documentation, but as we can see, some tests are failed. Generally, useful in web projects.
Qt3: Provides very basic Unicode support, no reason to use any more, especially when Qt4.5 is released under LGPL.
C++/STL: Even basic support exists, the API is not too friendly to STL containers and requires explicit usage of char * or wchar_t * and manual buffers allocation.
Glib: Gives quite good basic functionality. But finding word boundaries with Pango is really painful and does not work with Chinese. It has very nice C API and quite well documented. It uses internally utf-8 which makes the life easier when working with C strings. It still requires wrapping its functionality with C++ classes or grabbing huge GtkMM.
Python: has very basic native Unicode support. PyICU has terrible documentation.
Java: JDK provides quite good Unicode support, it can be quite easily replaced by ICU4J (actually most of JDK is based on ICU).
Summary
It is a shame that in 2009 there is no high quality, well documented, C++ friendly toolkit to work with Unicode.
- For real purposes I would take QtCode part of Qt4 or wrap ICU library with friendly API.
- Glib is good as well and, what is very important is its high availability on most UNIX systems.
When there will be Boost.ICU or Boost.Unicode just like there is Boost.Math or Boost.Asio?
Is Data Base the Bottle Neck of Web Service?
One of most common knowledge of many web developers is the assumption the data base is the bottle neck of their web services. Indeed, if the search in the database takes 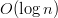 , it is probably the one that should take most of the time because most of other processing should take
, it is probably the one that should take most of the time because most of other processing should take
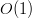 .
.
However, the complexity theory tells one important thing... 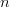 should should be sufficiently big. How much is that? 1GB, 1,000GB, 1,000,000GB or even more?
should should be sufficiently big. How much is that? 1GB, 1,000GB, 1,000,000GB or even more?
So let's take as an example on of the biggest web projects: Wikipedia, or Wikimedia's Server Farm.
The facts:
- WikiMedia's Server Farm includes about 300 servers.
- The main web page path includes:
- 95 Squids servers --- the upstream cachers that are responsible on 78% of performance (the hit ratio)
- 144 Apache+PHP servers that create the rest 22% of pages.
- 20 MySQL Master Slave servers.
- Other servers are used for other various purposes like search, static files, images rescaling and more.
- Memcached improves by additional 7% of hit ratio for the apache servers.
So, how the SQL servers can be the bottle neck of the system when they are about less then 10% of the server farm? Assuming balanced system, it is obvious that Apache and PHP consume most of computation resources of WikiMedia server farm.
So:
Is Data Base is the Bottle Neck of Web Service?
Definitly not.
Would switch to CppCMS server side technology would improve the performance
Definitly yes.

{kind=link}